Elasticsearch
Elasticsearch
Elasticsearch(以下称之为 ES)是一款基于 Lucene 的分布式全文搜索引擎,擅长海量数据存储、数据分析以及全文检索查询,它是一款非常优秀的数据存储与数据分析中间件,广泛应用于日志分析以及全文检索等领域,目前很多大厂都基于 Elasticsearch 开发了自己的存储中间件以及数据分析平台。
优势
速度快:因为它是基于Lucene 构建的,所以在执行查询时非常快速。此外,它还支持近实时搜索,可以在数据插入后的几秒钟内进行搜索。
扩展性强:Elasticsearch 是分布式的,能轻松地通过增加节点来扩展集群,从而处理更大量的数据和更高的查询需求。
高可用性:通过集群的形式部署,支持数据的分片和复制,即使某个节点失效也不会影响服务的整体运行。
多种类型的搜索和分析:不仅支持全文搜索,还支持结构化搜索、地理位置搜索、模糊搜索等,可以对数据进行多维度的复杂查询。
强大的REST APl:Elasticsearch 提供强大的 restfulAPI,使得其易于与各类编程语言和框架进行集成。
应用场景
网站搜索:公司的网站常常需要功能强大目快速的内部按索引擎,,比如电商网站使用 Elasticsearch 提供商品搜索功能,通过分词以及模糊匹配等技术来提高用户搜索体验。
日志分析:与Logstash 和 Kibana 结合,组成 ELK堆栈,能对大规模日志数据进行实时分析和可视化展示,是许多公司进行业务监控和安全分析的重要工具。
数据分析:通过高速的搜索能力和强大的数据处理能力,支持复杂的数据分析流程。这在金融、医药、网络安全等领域非常常见。
实时业务监控:比如监控服务器运行状况、用户行为分析与跟踪等需要实时数据更新和快速响应的应用。
document
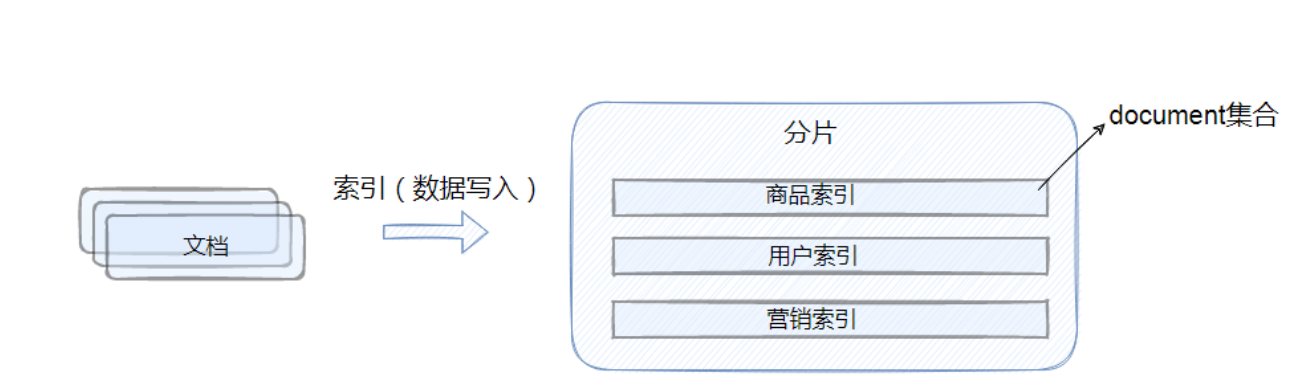
我们都说 ES 是面向 document 的,这句话什么意思呢?实际就是表示 ES 是基于 document 进行数据操作的,操作主要包括数据搜索以及索引(这里的索引时数据写入的意思)。因此可以说 document 是 ES 的基础数据结构,它会被序列化之后保存到 ES 中。相信大家都对 Mysql 还是比较熟悉的,因此我们用 Mysql 中的数据库与表的概念与 ES 的 index 进行对比,可能并不是十分的恰当和吻合,但是可以有助于大家对于这些概念的理解。另外 type 也在 ES6.x 版本之后逐渐取消了。
Index
在 ES 之前的版本中,是有 type 这个概念的,类比数据库中的表,那上文中所说的 document 就会放在 type 中。但是在 ES 后面的版本中为了提高数据存储的效率逐渐取消了 type,因此 index 实际上在现在的 ES 中既有库的概念也有表的概念。简单理解就是 index 就是文档的容器,它是一类文档的集合,但是这里需要注意的是 index 是逻辑空间的分类,实际数据是存在物理空间的分片上的。

另外需要说明的是,在 ES 中索引是有不同上下文含义的,它既可以是名词也可以是动词。索引为名词是就是上文中提到的它是 document 的集合,索引为动词的时候表示将 document 数据保存到 ES 中,也就是数据写入。
在 ES 中,为了屏蔽语言的交互差异,ES 直接对外的交互都是通过 Rest API 进行的。
倒排索引
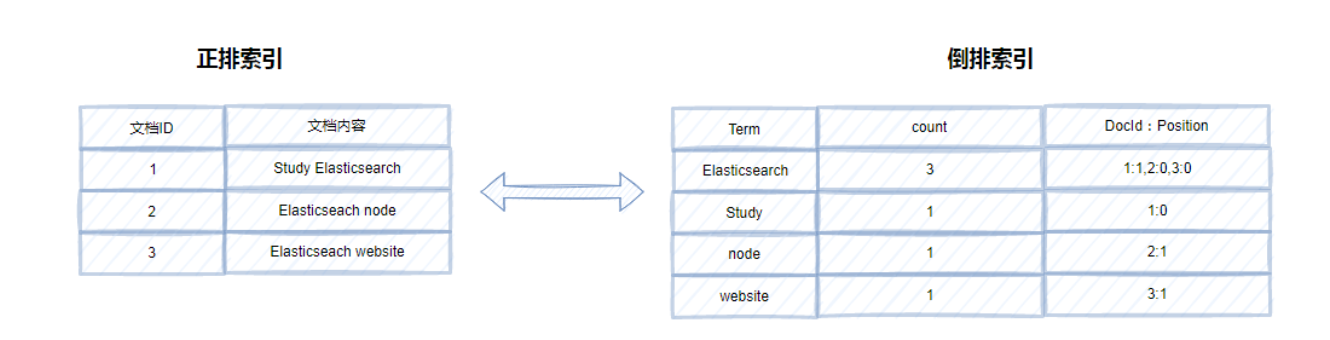
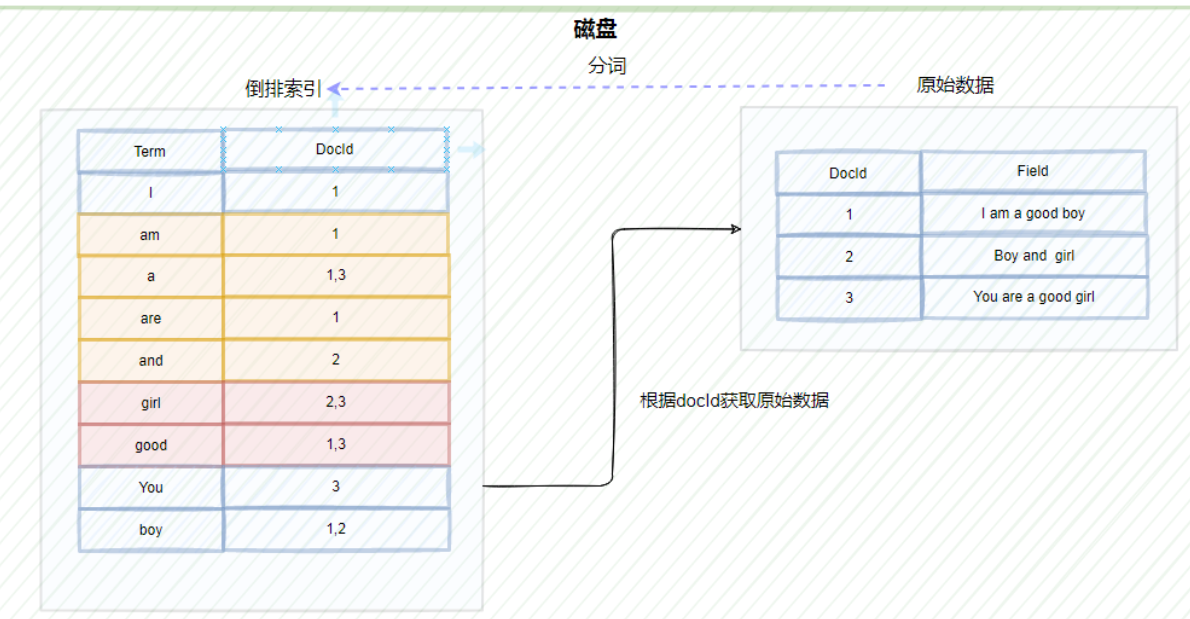
Elasticsearch使用倒排索引来实现快速搜索。倒排索引是一种将文档中出现的每个单词映射到一个包含该单词的所有文档列表的数据结构。
所谓正排索引就像书中的目录一样,根据页码查询内容,但是倒排索引确实相反的,它是通过对内容的分词,建立内容到文档 ID 的关联关系。这样在进行全文检索的时候,根据词典的内容便可以精确以及模糊查询,非常符合全文检索的要求。
用 B+树作为索引行不行呢?
全文索引就是需要支持对大文本进行索引的,从空间上来说 B+ 树不适合作为全文索引,同时 B+ 树因为每次搜索都是从根节点开始往下搜索,所以会遵循最左匹配原则,而我们使用全文搜索时,往往不会遵循最左匹配原则,所以可能会导致索引失效。这时候倒排索引就派上用场了。
倒排索引的组成
倒排索引的结构主要包括了两大部分一个是 Term Dictionary(单词词典),另一个是 Posting List(倒排列表)。
Term Dictionary(单词词典)记录了所用文档的单词以及单词和倒排列表的关系。
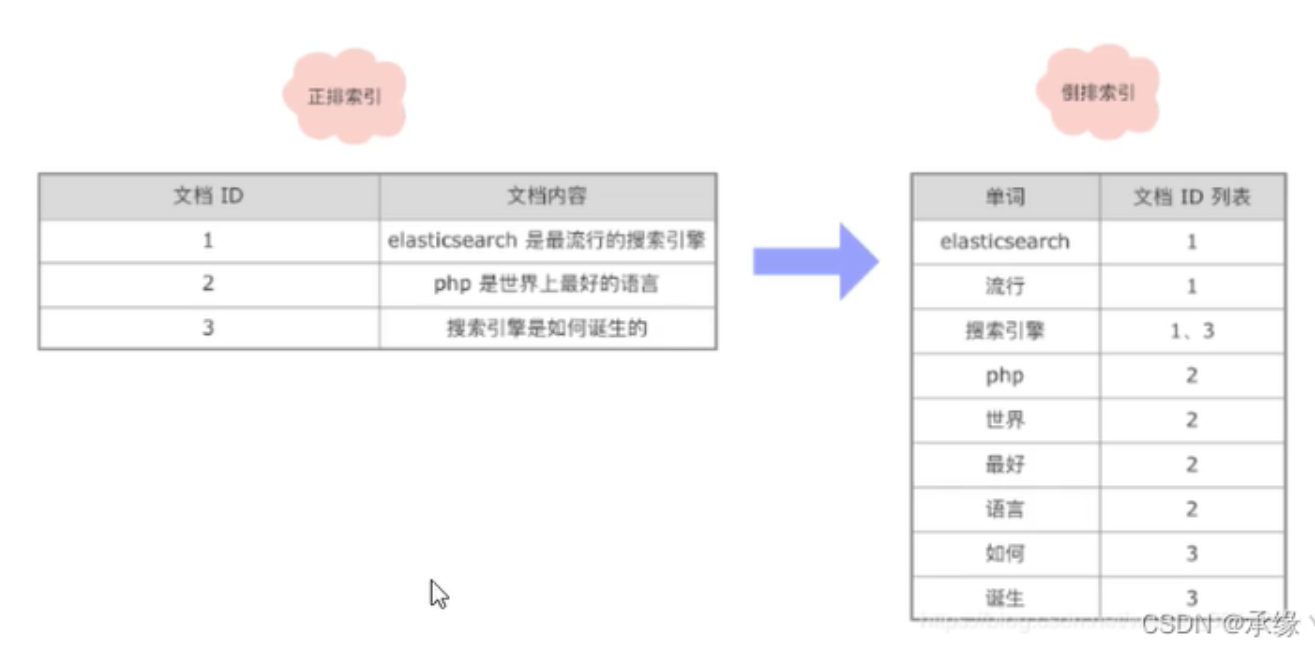
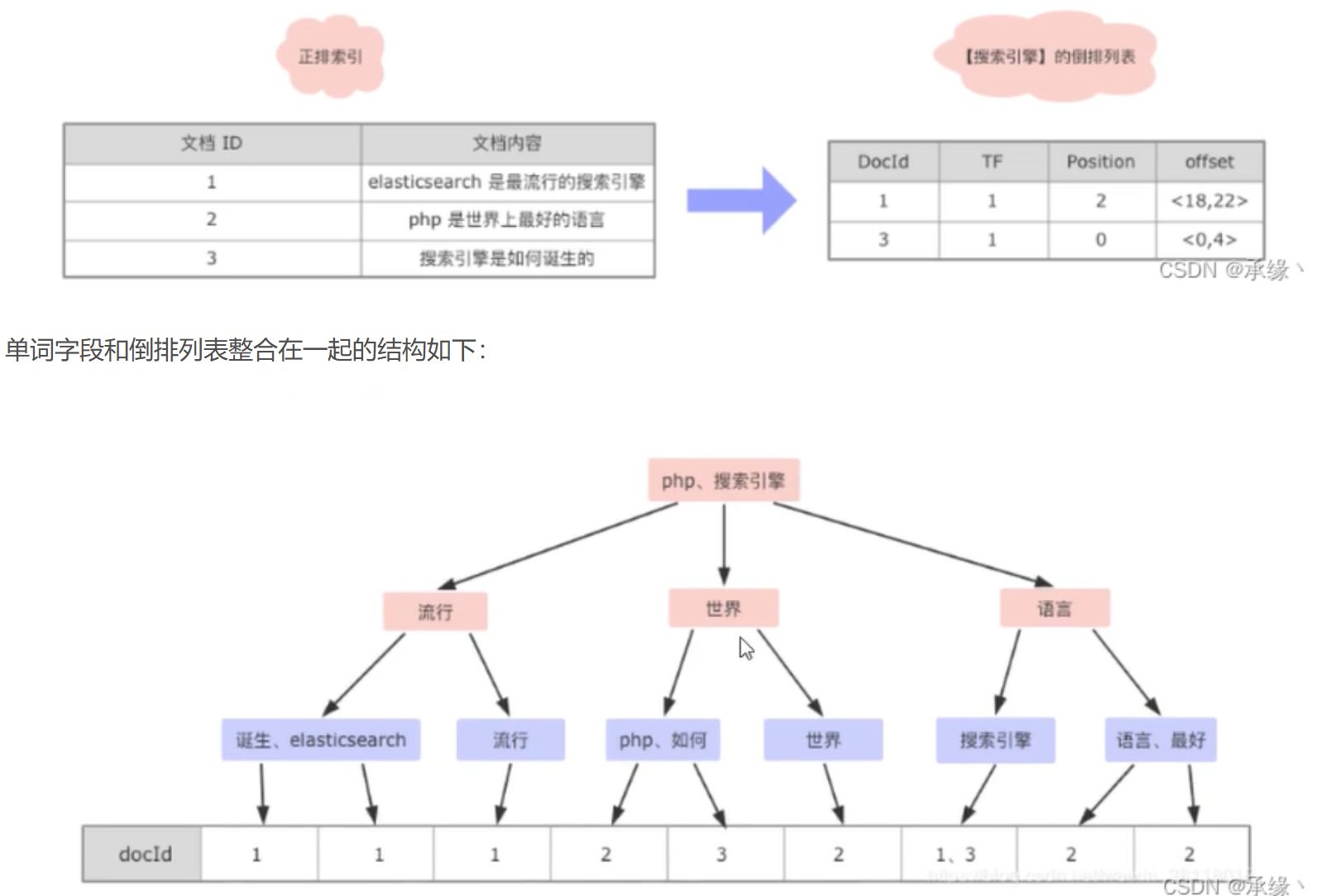
Posting List(倒排列表)则是记录了 term 在文档中的位置以及其他信息,主要包括文档 ID,词频(term 在文档中出现的次数,用来计算相关性评分),位置以及偏移(实现搜索高亮)。
倒排列表存储在磁盘文档中,主要包含一下信息:文档ID,单词频率(TF:Term Frequency),位置(Position),偏移(Offset)
FST有限状态传感器
如上文所述,在进行全文检索的时候,通过倒排索引中 term 与 docId 的关联关系获取到原始数据。但是这里有一个问题,ES 底层依赖 Lucene 实现倒排索引的,因此在进行数据写入的时候,Lucene 会为原始数据中的每个 term 生成对应的倒排索引,因此造成的结果就是倒排索引的数据量就会很大。而倒排索引对应的倒排表文件是存储在硬盘上的。如果每次查询都直接去磁盘中读取倒排索引数据,在通过获取的 docId 再去查询原始数据的话,肯定会造成多次的磁盘 IO,严重影响全文检索的效率。因此我们需要一种方式可以快速定位到倒排索引中的 term。大家想想使用什么方式比较好呢?可以考虑 HashMap, TRIE, Binary Search Tree 或者 Tenary Search Tree 等数据结构,实际上 Lucene 实际是使用了 FST(Finite State Transducer)有限状态传感器来实现二级索引的设计,它其实就是一种有限状态机。
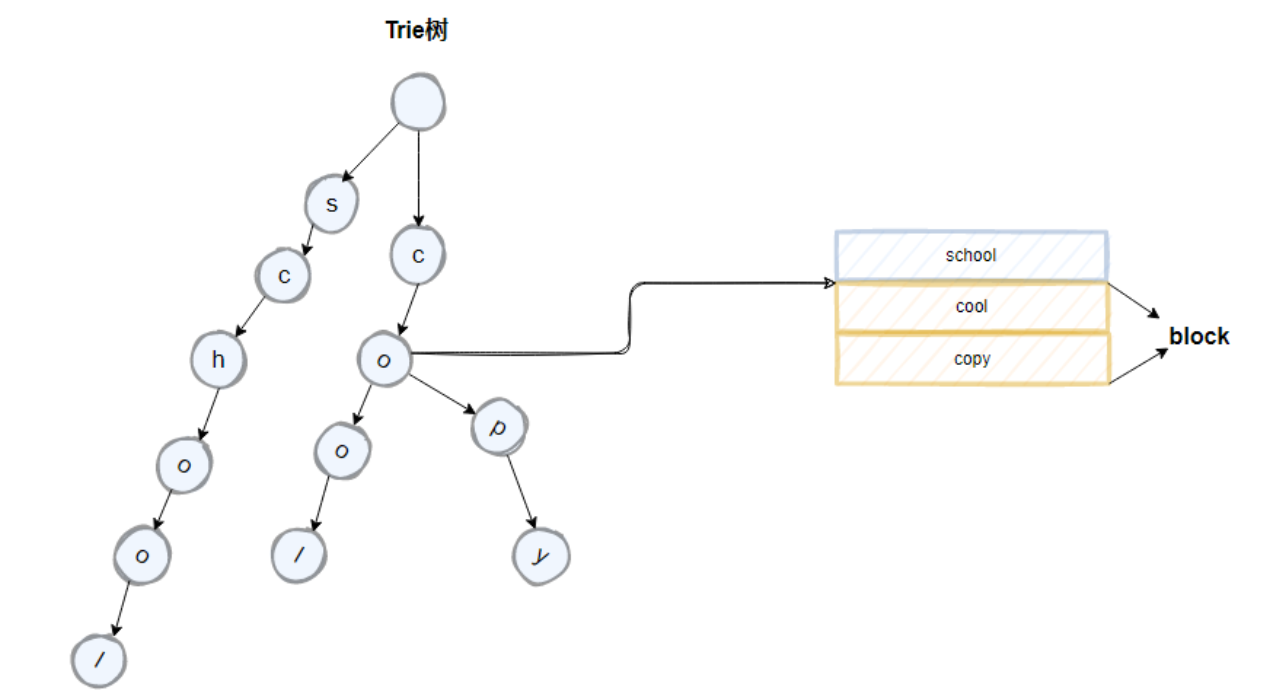
我们先来看下 trie 树的结构,在 Lucene 中是这样做的,将倒排索引中具有公共前缀的 term 组成一个 block,如下图所示的 cool 以及 copy,它们拥有 co 的公共前缀,按照类似前缀树的逻辑来构成 trie 树,对应节点中携带 block 的首地址。我们来分析下 trie 树相比 hashmap 有什么优点?hashmap 实现的是精准查找,但是 trie 树不仅可以实现精准查找,另外由于其公共前缀的特性还可以实现模糊查找。那我们再看 trie 树有什么地方可以再进行优化的地方?
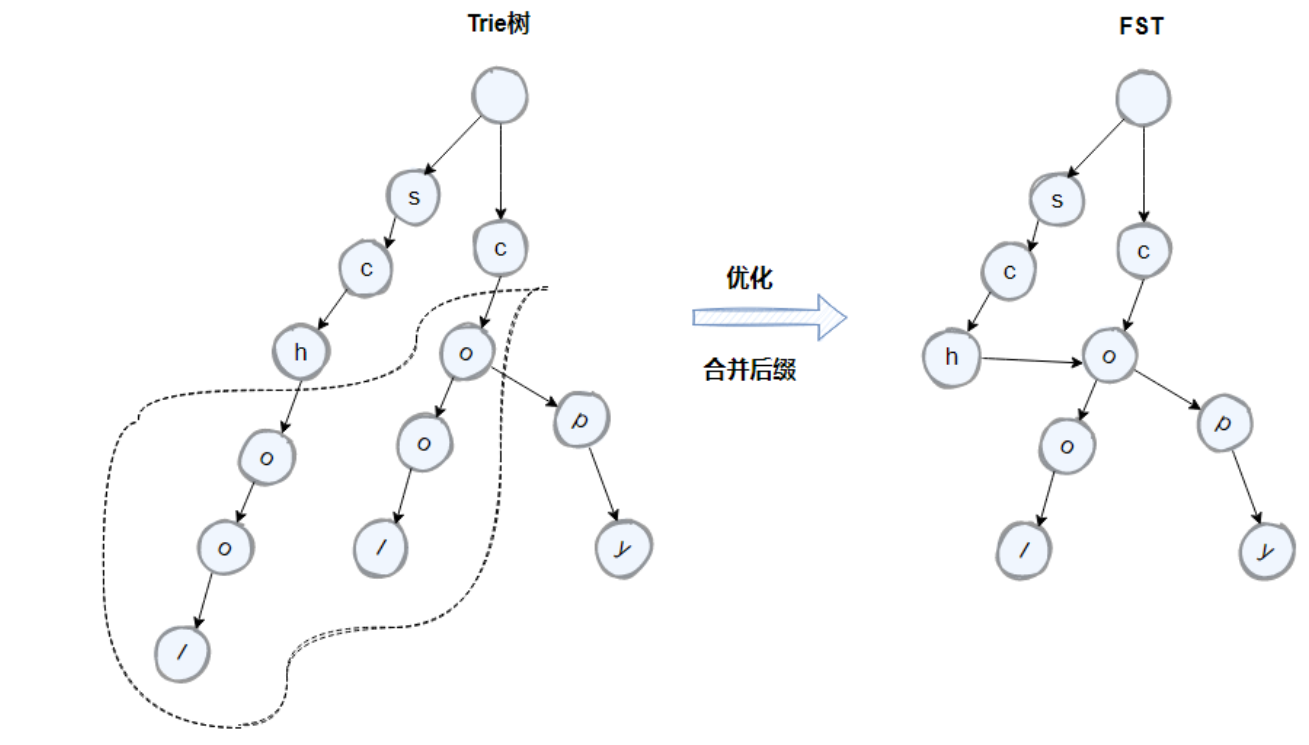
如上如所示,term 中的 school 以及 cool 的后面字符是一致的,因此我们可以通过将原先的 trie 树中的后缀字符进行合并来进一步的压缩空间。优化后的 trie 树就是 FST。
因此通过建立 FST 这个二级索引,可以实现倒排索引的快速定位,不需要经过多次的磁盘 IO,搜索效率大大提高了。不过需要注意的是 FST 是存储在堆内存中的,而且是常驻内存,大概占用 50%-70%的堆内存,因此这里也是我们在生产中可以进行堆内存优化的地方。
因此通过建立 FST 这个二级索引,可以实现倒排索引的快速定位,不需要经过多次的磁盘 IO,搜索效率大大提高了。不过需要注意的是 FST 是存储在堆内存中的,而且是常驻内存,大概占用 50%-70%的堆内存,因此这里也是我们在生产中可以进行堆内存优化的地方
参考:ES中的FST数据结构ElasticSearch在存储倒排索引时使用了FST数据结构,在大数据量的情况下极大的压缩占用空 - 掘金 (juejin.cn)
FST的优势
倒排索引:在Elasticsearch中,FST用于存储倒排索引中的词典部分。倒排索引的词典是用来记录所有存储Elasticsearch中的唯一词项。因为FST可以高效地压缩和查询大规模的字符串集合,它在管理和查询这些词项时表现得非常出色。具体来说,FST允许快速查找一个词项是否存在,并可以高效地进行前缀搜索。
自动补全:FST还用于实现Elasticsearch的自动补全功能。自动补全功能要求在输入前缀时能够快速找到所有符合前缀的可能词项。通过FST,Elasticsearch可以高效地苏行前缀查询,提供高速的自动补全服务。
拼写纠正:拼写纠正也离不开FST。这在处理用户可能输入的错误单词时尤为重要。elasticsearch使用FST来建立词汇表,并基于此进行纠错和建议,比如建议正确的单词拼写或替代选项。
性能优化:在Elasticsearch的优化过程中,FST通过前缀压缩的方式大大减少了词典的存储空间,从而提高了查询效率。特别是在处理包含大量词项的数据集时,FST的效率优势尤为明显。
索引存储:FST不仅在查询阶段发挥作用,还在索引创建阶段有所贡献。在索引创建时,FST帮助压缩存储需要索引的词项数据,使索引存储更加高效,节省存储空间的同时也提升了检索速度。
总的来说,FST在Elasticsearch中的应用不仅优化了存储空间,还极大地提升了査询效率,使得Elasticsearch能够在处理大规模数据和高并发查询时表现得更加出色。
Elasticsearch 的评分算法是如何工作的?它基于哪些因素计算相关性得分?
Elasticsearch 的评分算法主要基于 BM25(Best Matching 25)算法,这是一种改进的 TF-IDF 算法。它通过计算每个文档和查询之间的相关性得分来排序结果。相关性得分基于以下几个主要因素:
1)TF(Term Frequency):词频,某个词在文档中出现的次数。出现次数越多,该词对该文档的重要性越大。
2)IDF(Inverse Document Frequency):逆文档频率,用于衡量一个词在所有文档中有多重要。出现频率越低,IDF 越高,反之亦然。
3)Field Length Norm(规范化字段长度):字段的长度。一般来说,较短的字段如果包含查询词,那么该字段的相关性得分会更言。
4)Document Norms(文档规范化):这是对文档多个字段进行规范化处理的一个综合得分。
总得来说,Elasticsearch 的评分算法即是通过这些因素来计算每个文档的相关性得分,并将得分高的文档返回给用户