设计一个点赞系统
如何设计一个点赞系统?
库表设计
我们需要创建两张表:一张是点赞记录表,用于存储每个用户的点赞记录;另一张是 点赞数汇总表,用于存储每个项目的总点赞数。
点赞记录表:
1 | |
点赞数汇总表:
1 | |
缓存设计
点赞记录
对于作品的用户点赞记录,可以使用post:likes:{postId}作为Redis的key,其中{postId}是作品的唯一标识。值则是一个ZSet,包含所有点赞该作品的用户ID和对应的点赞时间戳
对于用户点赞记录,可以使用user:likes:{userId}作为key,其中{userId}是用户的唯一标识。值是一个ZSet,包含用户点赞过的所有作品ID和对应的点赞时间戳
要注意ZSet要限定长度,不然会有bigkey问题
点赞数量
对于作品的点赞数量,使用使用post:count:{postId}作为key,其中 {postId} 是帖子的唯一标识符。可以使用(String)或者(Set)数据结构来存储点赞数量,因为它是简单的值存储,适合用来记录计数。例如,使用 INCR 命令来原子性地增加帖子的点赞数量。
- 虽然点赞操作首先在缓存中进行,但为了数据的持久化,需要定期将缓存中的点赞数量同步到数据库中。
- 可以设置一个定时任务,比如每隔几分钟,将Redis中的点赞数量与数据库中的数据进行对比并更新。
幂等性
数据库保证幂等性
如果表中不存在该点赞记录,插入到表中,如果表中存在该点赞记录,通过对比表中记录的时间戳,如果当前时间大于表中时间戳,判断其点赞状态,如果是未点赞,重新设置成点赞状态。这样可以避免重复点赞带来的幂等性问题
缓存幂等性
使用 INCR 命令来原子性地增加帖子的点赞数量,可以避免并发条件下点赞幂等性问题
性能优化
数据库优化
为查询添加索引来提高查询性能,特别是在高并发的情况下
1 | |
分库分表
对于数据量较大的表,可以采用分库分表降低单点压力,比如like_record表
热点key问题
如果出现某个作品流量激增,有可能导致redis节点压力过大,这就属于热点key问题,可以在Java层代码加入一个本地缓存来缓解压力。如果发现热点key,通过热点key的监控系统将热点key加载到本地缓存。
整体架构设计
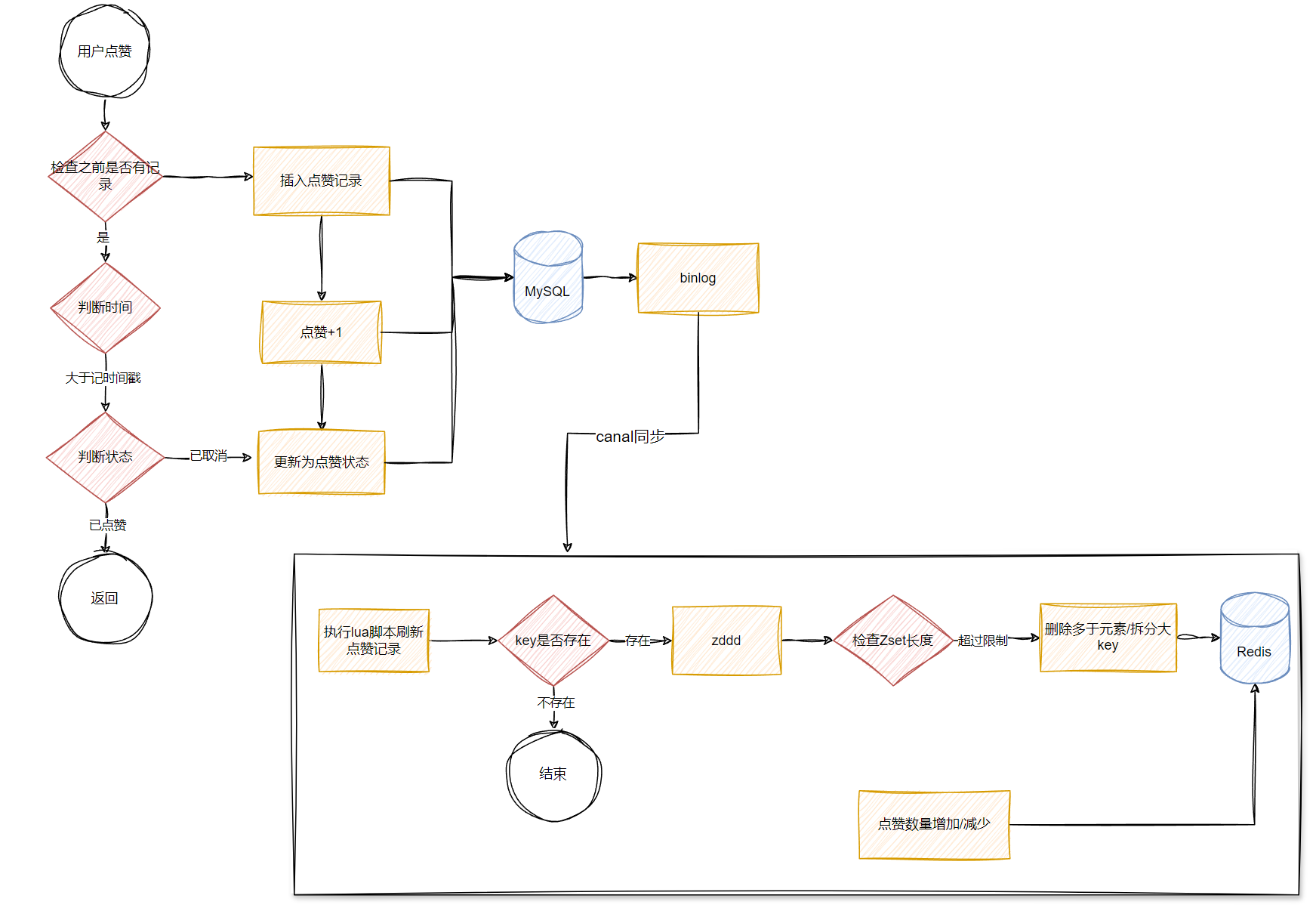
方案一
点赞服务对数据的实时性要求并没有那么高,可以采用先更新数据库,再订阅binlog的方式更新缓存,因为点赞是一个很频繁的动作,如果是删除key,只会加大了对db的查询,缓存的命中率会比较低,得不偿失。
这种操作会导致缓存数据的延迟,比如一个用户点赞了,但在缓存里面并没有实时更新,这个问题可以通过前端更新用户点赞数解决,比如用户点赞前先在缓存查询当前作品点赞数,点赞后直接在页面显示点赞+1的操作,后续的点赞数据一致性问题再通过补偿任务处理。
方案二
但是这种方式如果数据库压力过大,磁盘IO会面临严峻的考验,会导致数据库更新和binlog更新有延迟,导致redis里面数据的延迟
此时可以采用分库分表来缓解MySQL单表单库的压力,但是分库分表会引起系统的复杂性,比如数据倾斜,某些热点作品被频繁访问
点赞操作其实是KV操作,可以引入KV数据库,如Hbase,同时可以引入MQ为数据削峰填谷
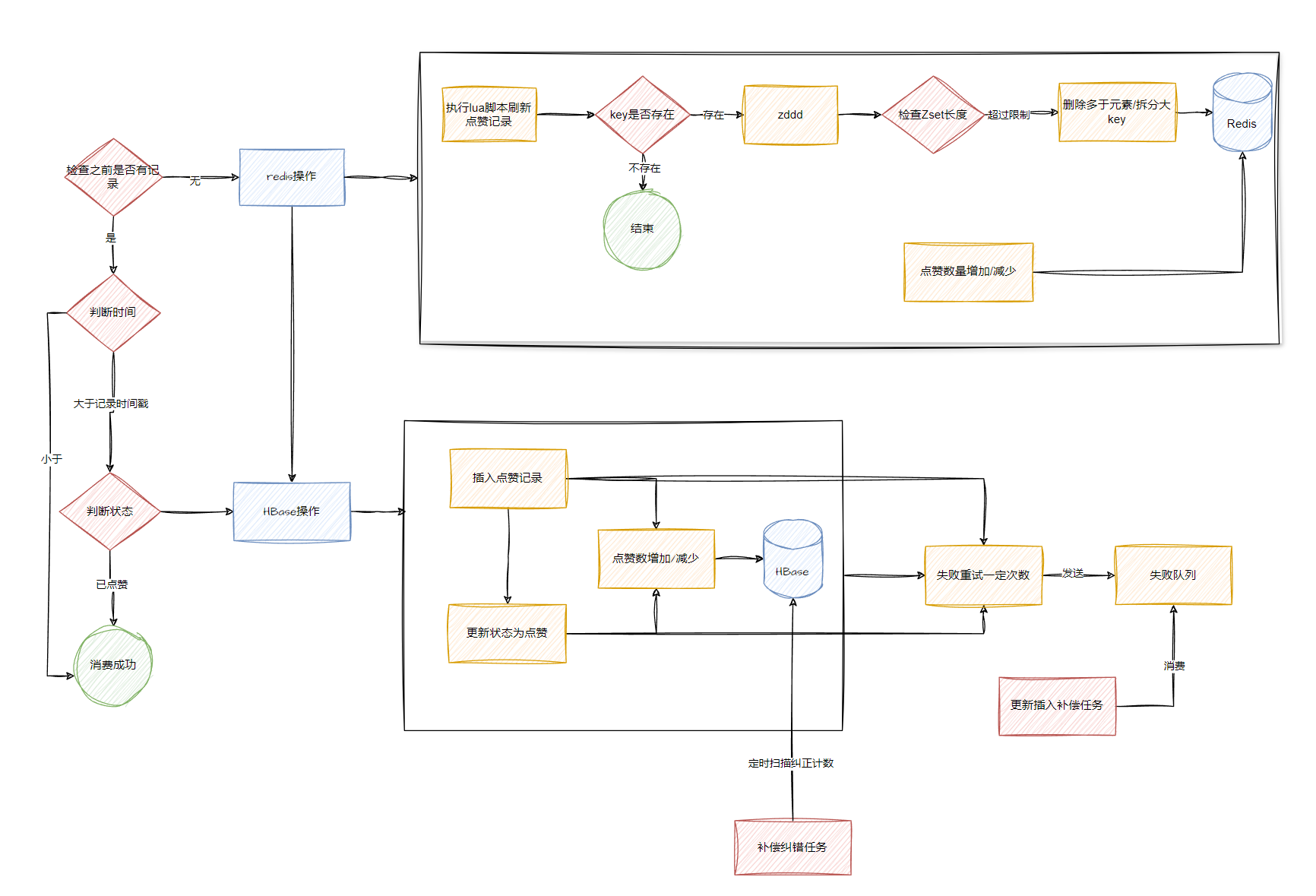
先写入redis可以让前端尽早看到最新的数据,这里redis的失败是可以允许的,在缓存失效过期后查询到最新的数据
Hbase因为没有事务机制,插入和更新操作如果失败了要进行重试,重试一定次数后可以发送到失败队列,让补偿任务消费补偿
而对于点赞数量加减操作,为了降低系统复杂度,不需要保证幂等性,可以由另外的定时的补偿任务来进行纠错
容灾备份
MySQL主从复制与容灾备份
主库配置
1 | |
从库配置
1 | |