RPC
RPC
RPC(Remote Procedure Call) 即远程过程调用,通过名字我们就能看出 RPC 关注的是远程调用而非本地调用。
为什么要 RPC ? 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP 还是 UDP)、序列化方式等等方面。
RPC 能帮助我们做什么呢? 简单来说,通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且!我们不需要了解底层网络编程的具体细节。
举个例子:两个不同的服务 A、B 部署在两台不同的机器上,服务 A 如果想要调用服务 B 中的某个方法的话就可以通过 RPC 来做。
一言蔽之:RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。
RPC 的原理是什么?
为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 5 个部分实现的:
- 客户端(服务消费端):调用远程方法的一端。
- 客户端 Stub(桩):这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
- 网络传输:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
- 服务端 Stub(桩):这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
- 服务端(服务提供端):提供远程方法的一端。
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。

- 服务消费端(client)以本地调用的方式调用远程服务;
- 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):
RpcRequest; - 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
- 服务端 Stub(桩)收到消息将消息反序列化为 Java 对象:
RpcRequest; - 服务端 Stub(桩)根据
RpcRequest中的类、方法、方法参数等信息调用本地的方法; - 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:
RpcResponse(序列化)发送至消费方; - 客户端 Stub(client stub)接收到消息并将消息反序列化为 Java 对象:
RpcResponse,这样也就得到了最终结果。
有了 HTTP 协议,为什么还要有 RPC ?
- 纯裸 TCP 是能收发数据,但它是个无边界的数据流,上层需要定义消息格式用于定义 消息边界 。于是就有了各种协议,HTTP 和各类 RPC 协议就是在 TCP 之上定义的应用层协议。
- RPC 本质上不算是协议,而是一种调用方式,而像 gRPC 和 Thrift 这样的具体实现,才是协议,它们是实现了 RPC 调用的协议。目的是希望程序员能像调用本地方法那样去调用远端的服务方法。同时 RPC 有很多种实现方式,不一定非得基于 TCP 协议。
- 从发展历史来说,HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。 很多软件同时支持多端,所以对外一般用 HTTP 协议,而内部集群的微服务之间则采用 RPC 协议进行通讯。
- RPC 其实比 HTTP 出现的要早,且比目前主流的 HTTP1.1 性能要更好,所以大部分公司内部都还在使用 RPC。
- HTTP2.0 在 HTTP1.1 的基础上做了优化,性能可能比很多 RPC 协议都要好,但由于是这几年才出来的,所以也不太可能取代掉 RPC。
HTTP和RPC的区别
RPC 其实是一种调用方式
我们回过头来看网络的分层图。
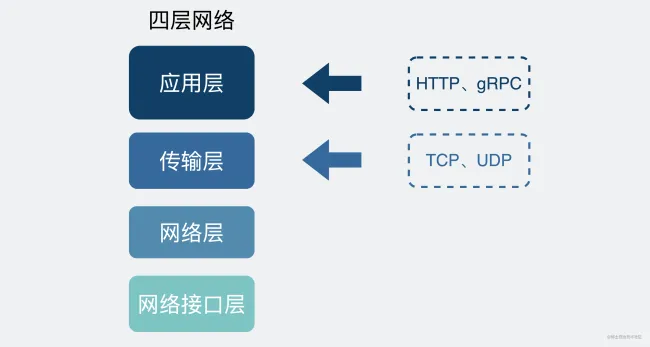
TCP 是传输层的协议 ,而基于 TCP 造出来的 HTTP 和各类 RPC 协议,它们都只是定义了不同消息格式的 应用层协议 而已
HTTP(Hyper Text Transfer Protocol)协议又叫做 超文本传输协议 。我们用的比较多,平时上网在浏览器上敲个网址就能访问网页,这里用到的就是 HTTP 协议。
而 RPC(Remote Procedure Call)又叫做 远程过程调用,它本身并不是一个具体的协议,而是一种 调用方式
举个例子,我们平时调用一个 本地方法 就像下面这样
1 | |
如果现在这不是个本地方法,而是个远端服务器暴露出来的一个方法remoteFunc,如果我们还能像调用本地方法那样去调用它,这样就可以屏蔽掉一些网络细节,用起来更方便,岂不美哉?
1 | |

基于这个思路,大佬们造出了非常多款式的 RPC 协议,比如比较有名的gRPC,thrift。
值得注意的是,虽然大部分 RPC 协议底层使用 TCP,但实际上 它们不一定非得使用 TCP,改用 UDP 或者 HTTP,其实也可以做到类似的功能。
服务发现
首先要向某个服务器发起请求,你得先建立连接,而建立连接的前提是,你得知道 IP 地址和端口 。这个找到服务对应的 IP 端口的过程,其实就是 服务发现。
在 HTTP 中,你知道服务的域名,就可以通过 DNS 服务 去解析得到它背后的 IP 地址,默认 80 端口。
而 RPC 的话,就有些区别,一般会有专门的中间服务去保存服务名和 IP 信息,比如 Consul、Etcd、Nacos、ZooKeeper,甚至是 Redis。想要访问某个服务,就去这些中间服务去获得 IP 和端口信息。由于 DNS 也是服务发现的一种,所以也有基于 DNS 去做服务发现的组件,比如 CoreDNS。
可以看出服务发现这一块,两者是有些区别,但不太能分高低。
底层连接形式
以主流的 HTTP1.1 协议为例,其默认在建立底层 TCP 连接之后会一直保持这个连接(keep alive),之后的请求和响应都会复用这条连接。
而 RPC 协议,也跟 HTTP 类似,也是通过建立 TCP 长链接进行数据交互,但不同的地方在于,RPC 协议一般还会再建个 连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,可以说非常环保。

由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池,比如 Go 就是这么干的。
可以看出这一块两者也没太大区别,所以也不是关键
传输的内容
基于 TCP 传输的消息,说到底,无非都是 消息头 Header 和消息体 Body。
Header 是用于标记一些特殊信息,其中最重要的是 消息体长度。
Body 则是放我们真正需要传输的内容,而这些内容只能是二进制 01 串,毕竟计算机只认识这玩意。所以 TCP 传字符串和数字都问题不大,因为字符串可以转成编码再变成 01 串,而数字本身也能直接转为二进制。但结构体呢,我们得想个办法将它也转为二进制 01 串,这样的方案现在也有很多现成的,比如 JSON,Protocol Buffers (Protobuf) 。
这个将结构体转为二进制数组的过程就叫 序列化 ,反过来将二进制数组复原成结构体的过程叫 反序列化。
HTTP
对于主流的 HTTP1.1,虽然它现在叫超文本协议,支持音频视频,但 HTTP 设计 初是用于做网页文本展示的,所以它传的内容以字符串为主。Header 和 Body 都是如此,是以JSON结构进行序列化的

可以看到这里面的内容非常多的冗余,显得非常啰嗦。最明显的,像 Header 里的那些信息,其实如果我们约定好头部的第几位是 Content-Type,就不需要每次都真的把 Content-Type 这个字段都传过来,类似的情况其实在 Body 的 JSON 结构里也特别明显。
RPC
而 RPC,因为它定制化程度更高,可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的。因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因。
当然上面说的 HTTP,其实 特指的是现在主流使用的 HTTP1.1,HTTP2在前者的基础上做了很多改进,所以 性能可能比很多 RPC 协议还要好,甚至连gRPC底层都直接用的HTTP2。
为什么既然有了 HTTP2,还要有 RPC 协议?
这个是由于 HTTP2 是 2015 年出来的。那时候很多公司内部的 RPC 协议都已经跑了好些年了,基于历史原因,一般也没必要去换了。