Redis集群
Redis集群
Redis 集群是 Redis 数据库的分布式解决方案,旨在提供高可用性和扩展性。它允许将数据分布存储在多个节点上,从而提高了系统的性能和容错能力。
主从复制模式
主从复制是 Redis 高可用服务的最基础的保证,实现方案就是将从前的一台 Redis 服务器,同步数据到多台从 Redis 服务器上,即一主多从的模式,且主从服务器之间采用的是「读写分离」的方式。
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
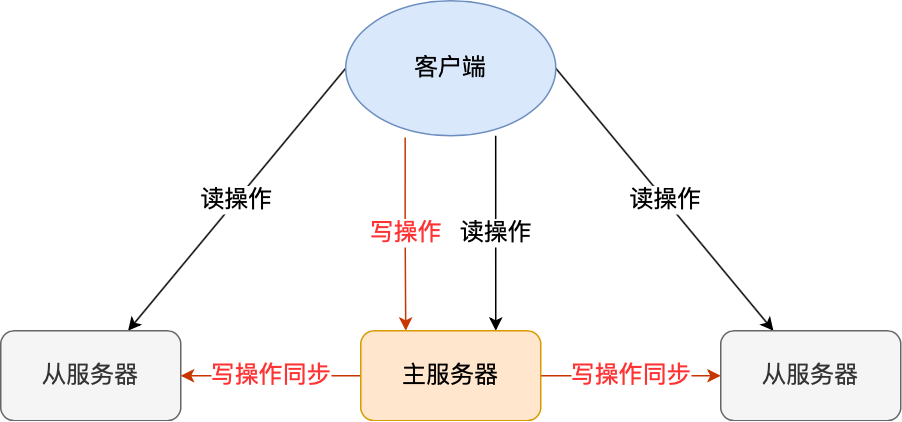
也就是说,所有的数据修改只在主服务器上进行,然后将最新的数据同步给从服务器,这样就使得主从服务器的数据是一致的。
注意,主从服务器之间的命令复制是异步进行的。
具体来说,在主从服务器命令传播阶段,主服务器收到新的写命令后,会发送给从服务器。但是,主服务器并不会等到从服务器实际执行完命令后,再把结果返回给客户端,而是主服务器自己在本地执行完命令后,就会向客户端返回结果了。如果从服务器还没有执行主服务器同步过来的命令,主从服务器间的数据就不一致了。
所以,无法实现强一致性保证(主从数据时时刻刻保持一致),数据不一致是难以避免的。
哨兵机制
为什么要有哨兵机制?
在 Redis 的主从架构中,由于主从模式是读写分离的,如果主节点(master)挂了,那么将没有主节点来服务客户端的写操作请求,也没有主节点给从节点(slave)进行数据同步了。
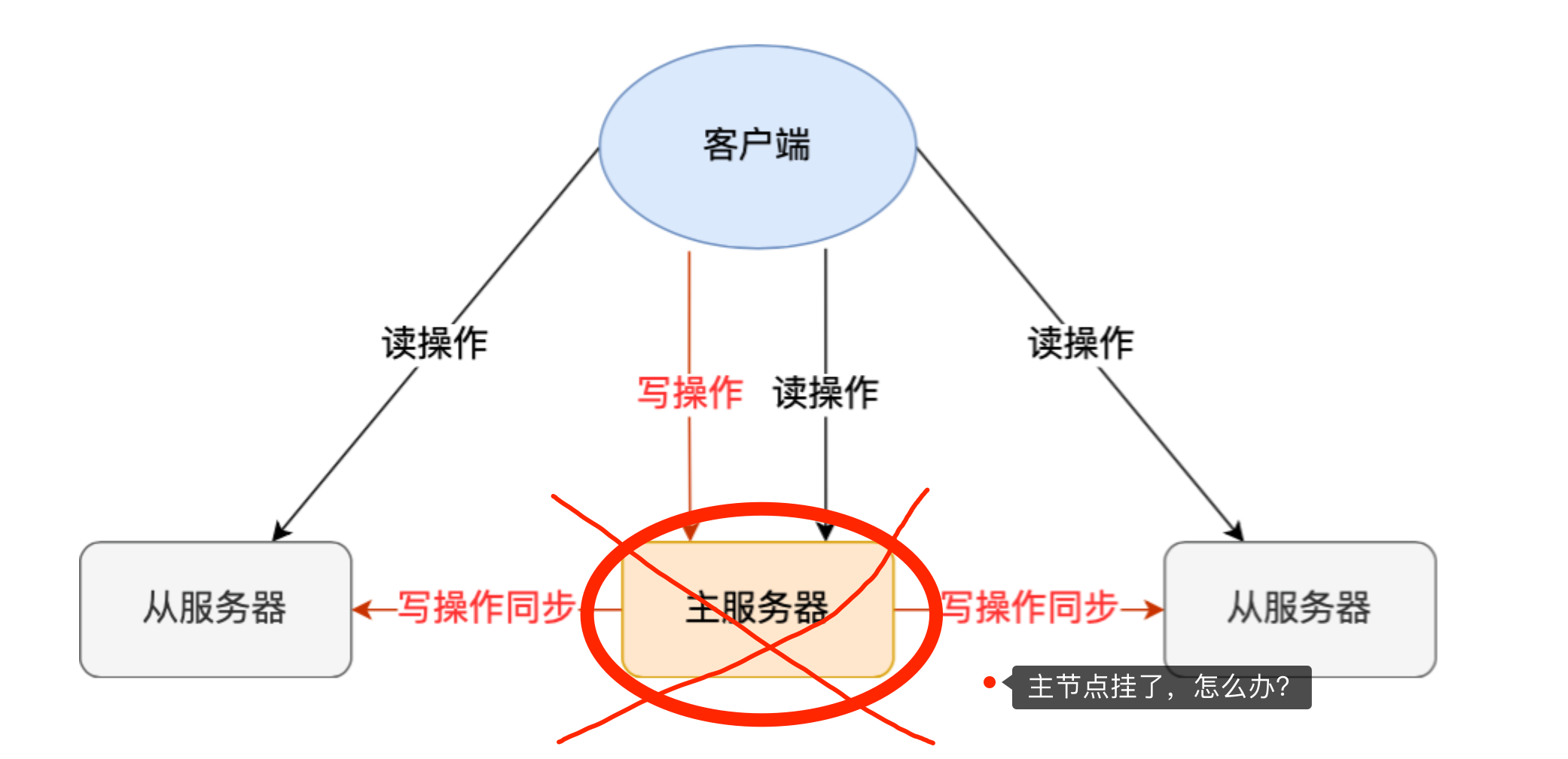
这时如果要恢复服务的话,需要人工介入,选择一个「从节点」切换为「主节点」,然后让其他从节点指向新的主节点,同时还需要通知上游那些连接 Redis 主节点的客户端,将其配置中的主节点 IP 地址更新为「新主节点」的 IP 地址。
这样也不太“智能”了,要是有一个节点能监控「主节点」的状态,当发现主节点挂了,它自动将一个「从节点」切换为「主节点」的话,那么可以节省我们很多事情啊。
Redis 在 2.8 版本以后提供的哨兵(Sentinel)机制,它的作用是实现主从节点故障转移。它会监测主节点是否存活,如果发现主节点挂了,它就会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端。
哨兵机制是如何工作的?
哨兵其实是一个运行在特殊模式下的 Redis 进程,所以它也是一个节点。从“哨兵”这个名字也可以看得出来,它相当于是“观察者节点”,观察的对象是主从节点。
当然,它不仅仅是观察那么简单,在它观察到有异常的状况下,会做出一些“动作”,来修复异常状态。
哨兵节点主要负责三件事情:监控、选主、通知。
哨兵节点通过 Redis 的发布者/订阅者机制,哨兵之间可以相互感知,相互连接,然后组成哨兵集群,同时哨兵又通过 INFO 命令,在主节点里获得了所有从节点连接信息,于是就能和从节点建立连接,并进行监控了。
1、第一轮投票:判断主节点下线
当哨兵集群中的某个哨兵判定主节点下线(主观下线)后,就会向其他哨兵发起命令,其他哨兵收到这个命令后,就会根据自身和主节点的网络状况,做出赞成投票或者拒绝投票的响应。
当这个哨兵的赞同票数达到哨兵配置文件中的 quorum 配置项设定的值后,这时主节点就会被该哨兵标记为「客观下线」

2、第二轮投票:选出哨兵 leader
某个哨兵判定主节点客观下线后,该哨兵就会发起投票,告诉其他哨兵,它想成为 leader,想成为 leader 的哨兵节点,要满足两个条件:
- 第一,拿到半数以上的赞成票;
- 第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
3、由哨兵 leader 进行主从故障转移
选举出了哨兵 leader 后,就可以进行主从故障转移的过程了。该操作包含以下四个步骤:
- 第一步:在已下线主节点(旧主节点)属下的所有「从节点」里面,挑选出一个从节点,并将其转换为主节点,选择的规则:
- 过滤掉已经离线的从节点;
- 过滤掉历史网络连接状态不好的从节点;
- 将剩下的从节点,进行三轮考察:优先级、复制进度、ID 号。在每一轮考察过程中,如果找到了一个胜出的从节点,就将其作为新主节点。
- 优先级:比如,如果「A 从节点」的物理内存是所有从节点中最大的,那么我们可以把「A 从节点」的优先级设置成最高。这样当哨兵进行第一轮考虑的时候,优先级最高的 A 从节点就会优先胜出,于是就会成为新主节点。
- 复制进度:主从架构中,主节点会将写操作同步给从节点,在这个过程中,主节点会用 master_repl_offset 记录当前的最新写操作在 repl_backlog_buffer 中的位置,而从节点会用 slave_repl_offset 这个值记录当前的复制进度。
- ID号:比较两个从节点的 ID 号,ID 号小的从节点胜出。
- 第二步:让已下线主节点属下的所有「从节点」修改复制目标,修改为复制「新主节点」;
- 第三步:将新主节点的 IP 地址和信息,通过「发布者/订阅者机制」通知给客户端;
- 第四步:继续监视旧主节点,当这个旧主节点重新上线时,将它设置为新主节点的从节点;
哨兵集群是如何进行通信的?
前面提到了 Redis 的发布者/订阅者机制,那就不得不提一下哨兵集群的组成方式,因为它也用到了这个技术。
在我第一次搭建哨兵集群的时候,当时觉得很诧异。因为在配置哨兵的信息时,竟然只需要填下面这几个参数,设置主节点名字、主节点的 IP 地址和端口号以及 quorum 值。
1 | |
不需要填其他哨兵节点的信息,我就好奇它们是如何感知对方的,又是如何组成哨兵集群的?
不同的的哨兵是如何相互感知的?
**哨兵节点之间是通过 Redis 的发布者/订阅者机制来相互发现的。
在主从集群中,主节点上有一个名为__sentinel__:hello的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
在下图中,哨兵 A 把自己的 IP 地址和端口的信息发布到__sentinel__:hello 频道上,哨兵 B 和 C 订阅了该频道。那么此时,哨兵 B 和 C 就可以从这个频道直接获取哨兵 A 的 IP 地址和端口号。然后,哨兵 B、C 可以和哨兵 A 建立网络连接。
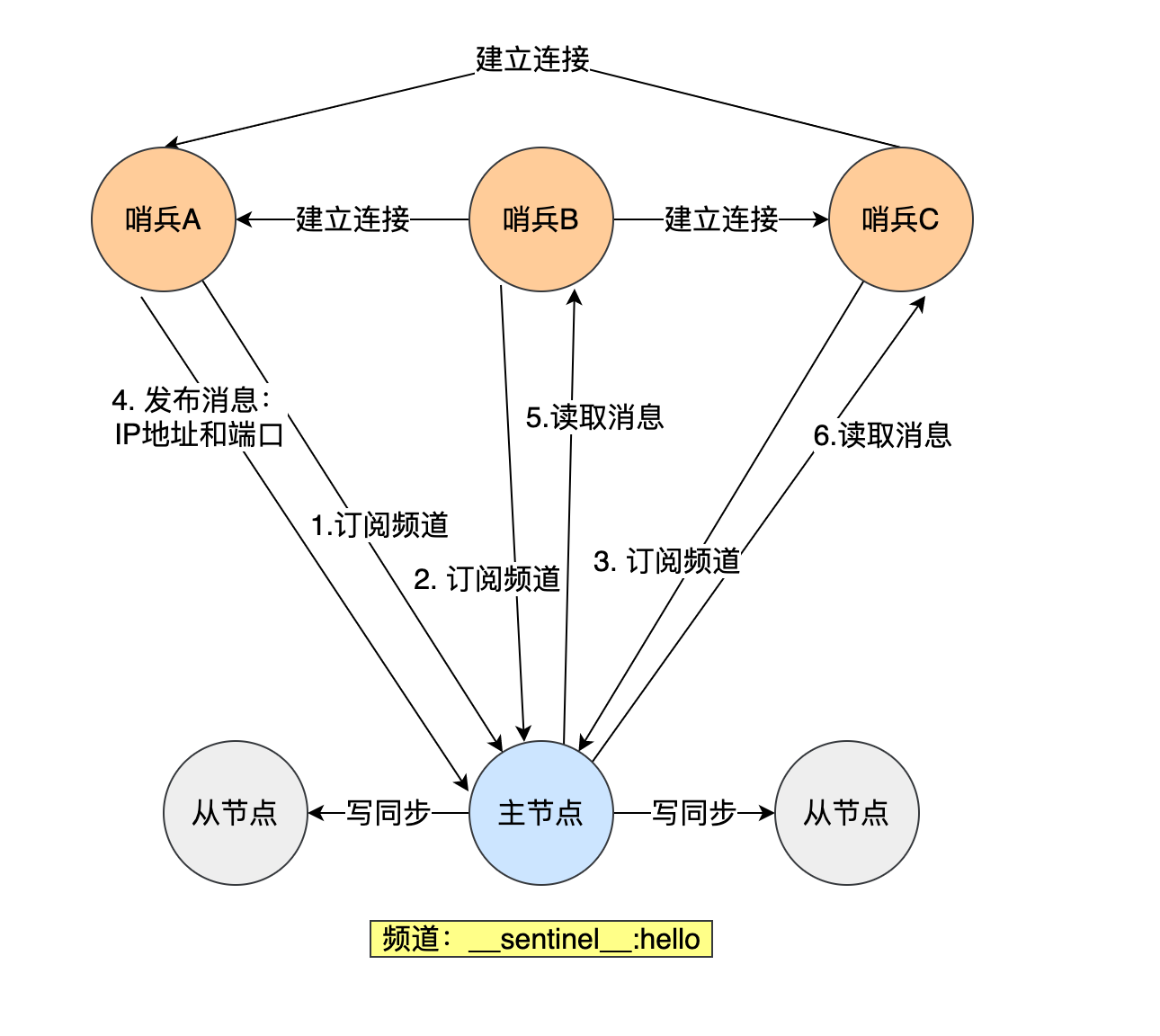
通过这个方式,哨兵 B 和 C 也可以建立网络连接,这样一来,哨兵集群就形成了。
哨兵集群会对「从节点」的运行状态进行监控,那哨兵集群如何知道「从节点」的信息?
主节点知道所有「从节点」的信息,所以哨兵会每 10 秒一次的频率向主节点发送 INFO 命令来获取所有「从节点」的信息。
如下图所示,哨兵 B 给主节点发送 INFO 命令,主节点接受到这个命令后,就会把从节点列表返回给哨兵。接着,哨兵就可以根据从节点列表中的连接信息,和每个从节点建立连接,并在这个连接上持续地对从节点进行监控。哨兵 A 和 C 可以通过相同的方法和从节点建立连接。
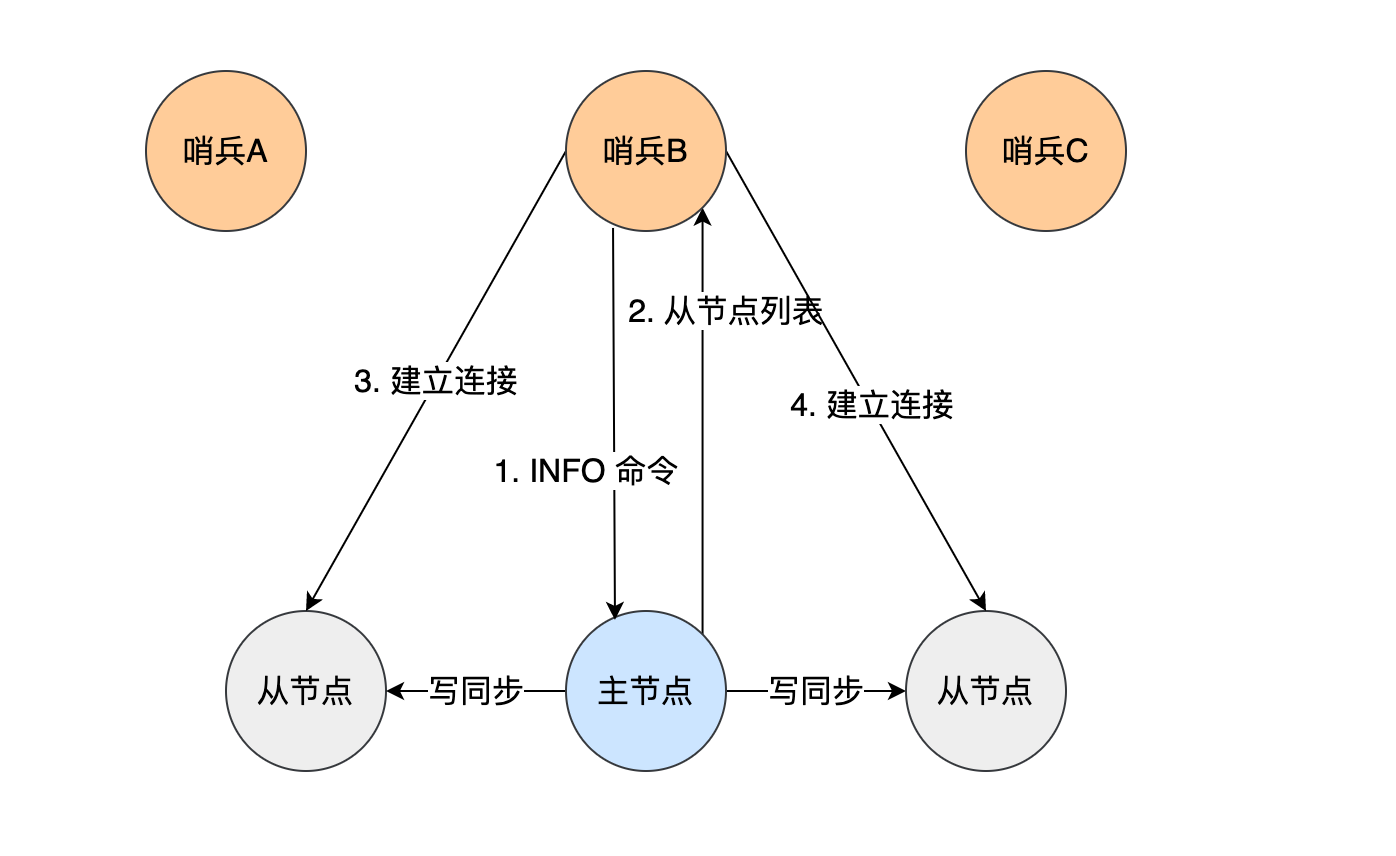
正是通过 Redis 的发布者/订阅者机制,哨兵之间可以相互感知,然后组成集群,同时,哨兵又通过 INFO 命令,在主节点里获得了所有从节点连接信息,于是就能和从节点建立连接,并进行监控了。
切片集群模式
哨兵集群模式无法做到扩容,并发压力受限于单个服务器的配置。
当 Redis 缓存数据量大到一台服务器无法缓存时,就需要使用 Redis 切片集群(Redis Cluster )方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
与哨兵集群模式的区别:切片集群是多主多从的架构,哨兵集群是一主多从的架构。
Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和节点之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中,具体执行过程分为两大步
- 根据键值对的 key,按照 CRC16 算法计算一个 16 bit 的值。
- 再用 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
接下来的问题就是,这些哈希槽怎么被映射到具体的 Redis 节点上的呢?有两种方案:
- 平均分配: 在使用 cluster create 命令创建 Redis 集群时,Redis 会自动把所有哈希槽平均分布到集群节点上。比如集群中有 9 个节点,则每个节点上槽的个数为 16384/9 个。
- 手动分配: 可以使用 cluster meet 命令手动建立节点间的连接,组成集群,再使用 cluster addslots 命令,指定每个节点上的哈希槽个数。
为了方便你的理解,我通过一张图来解释数据、哈希槽,以及节点三者的映射分布关系。
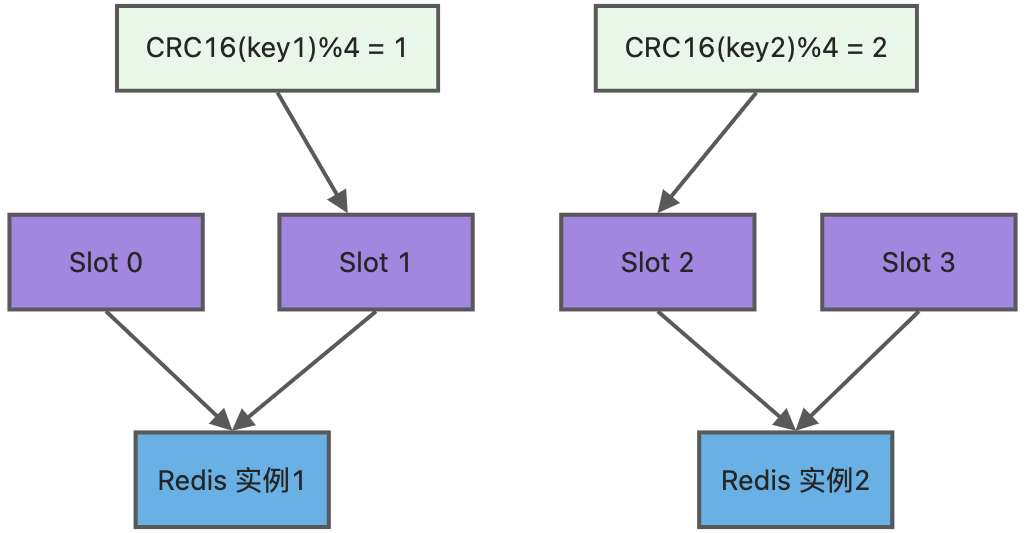
上图中的切片集群一共有 2 个节点,假设有 4 个哈希槽(Slot 0~Slot 3)时,我们就可以通过命令手动分配哈希槽,比如节点 1 保存哈希槽 0 和 1,节点 2 保存哈希槽 2 和 3。
1 | |
然后在集群运行的过程中,key1 和 key2 计算完 CRC16 值后,对哈希槽总个数 4 进行取模,再根据各自的模数结果,就可以被映射到哈希槽 1(对应节点1) 和 哈希槽 2(对应节点2)。
需要注意的是,在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
集群脑裂
先来理解集群的脑裂现象,这就好比一个人有两个大脑,那么到底受谁控制呢?
那么在 Redis 中,集群脑裂产生数据丢失的现象是怎样的呢?
在 Redis 主从架构中,部署方式一般是「一主多从」,主节点提供写操作,从节点提供读操作。 如果主节点的网络突然发生了问题,它与所有的从节点都失联了,但是此时的主节点和客户端的网络是正常的,这个客户端并不知道 Redis 内部已经出现了问题,还在照样的向这个主节点写数据(过程A),此时这些数据被旧主节点缓存到了缓冲区里,因为主从节点之间的网络问题,这些数据都是无法同步给从节点的。
这时,哨兵也发现主节点失联了,它就认为主节点挂了(但实际上主节点正常运行,只是网络出问题了),于是哨兵就会在「从节点」中选举出一个 leader 作为主节点,这时集群就有两个主节点了 —— 脑裂出现了。
然后,网络突然好了,哨兵因为之前已经选举出一个新主节点了,它就会把旧主节点降级为从节点(A),然后从节点(A)会向新主节点请求数据同步,因为第一次同步是全量同步的方式,此时的从节点(A)会清空掉自己本地的数据,然后再做全量同步。所以,之前客户端在过程 A 写入的数据就会丢失了,也就是集群产生脑裂数据丢失的问题。
总结一句话就是:由于网络问题,集群节点之间失去联系。主从数据不同步;重新平衡选举,产生两个主服务。等网络恢复,旧主节点会降级为从节点,再与新主节点进行同步复制的时候,由于会从节点会清空自己的缓冲区,所以导致之前客户端写入的数据丢失了
集群脑裂问题如何解决?
当主节点发现从节点下线或者通信超时的总数量超过一定的阈值时,那么禁止主节点进行写数据,直接把错误返回给客户端。
在 Redis 的配置文件中有两个参数我们可以设置:
- min-slaves-to-write x,主节点必须要有至少 x 个从节点连接,如果小于这个数,主节点会禁止写数据。
- min-slaves-max-lag x,主从数据复制和同步的延迟不能超过 x 秒,如果超过,主节点会禁止写数据。
我们可以把 min-slaves-to-write 和 min-slaves-max-lag 这两个配置项搭配起来使用,分别给它们设置一定的阈值,假设为 N 和 T。
这两个配置项组合后的要求是,主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的写请求了。
即使原主库是假故障,它在假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然也就无法和从库进行 ACK 确认了。这样一来,min-slaves-to-write 和 min-slaves-max-lag 的组合要求就无法得到满足,原主库就会被限制接收客户端写请求,客户端也就不能在原主库中写入新数据了。
等到新主库上线时,就只有新主库能接收和处理客户端请求,此时,新写的数据会被直接写到新主库中。而原主库会被哨兵降为从库,即使它的数据被清空了,也不会有新数据丢失。
举个例子:
假设我们将 min-slaves-to-write 设置为 1,把 min-slaves-max-lag 设置为 12s,把哨兵的 down-after-milliseconds 设置为 10s,主库因为某些原因卡住了 15s,导致哨兵判断主库客观下线,开始进行主从切换。
同时,因为原主库卡住了 15s,没有一个从库能和原主库在 12s 内进行数据复制,原主库也无法接收客户端请求了。
这样一来,主从切换完成后,也只有新主库能接收请求,不会发生脑裂,也就不会发生数据丢失的问题了。
Redis主从节点时长连接还是短连接?
长连接
减少连接开销:建立和断开连接都需要一定的时间和资源。使用长连接可以减少频繁建立和断开连接所带来的开销,提高了性能和效率。
减少网络开销:在长连接中,连接建立后,数据传输时不需要反复建立连接,减少了网络通信开销,提高了数据传输的效率。
实时性:长连接可以实现实时数据的传输和同步,主节点对数据的更新可以及时地同步到从节点,确保了数据的一致性。
简化管理:长连接可以避免频繁地管理连接的建立和关闭,减少了系统的复杂性和管理成本。
支持持久化:在 Redis 主从复制中,从节点需要通过长连接从主节点同步数据。长连接可以确保从节点能够持续地接收主节点的数据更新,实现持久化复制。
怎么判断 Redis 某个节点是否正常工作?
Redis 判断节点是否正常工作,基本都是通过互相的 ping-pong 心态检测机制,如果有一半以上的节点去 ping 一个节点的时候没有 pong 回应,集群就会认为这个节点挂掉了,会断开与这个节点的连接。
Redis 主从节点发送的心态间隔是不一样的,而且作用也有一点区别:
- Redis 主节点默认每隔 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态,可通过参数repl-ping-slave-period控制发送频率。
- Redis 从节点每隔 1 秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量,目的是为了:
- 实时监测主从节点网络状态;
- 上报自身复制偏移量, 检查复制数据是否丢失, 如果从节点数据丢失, 再从主节点的复制缓冲区中拉取丢失数据。
主从复制架构中,过期key如何处理?
主节点处理了一个key或者通过淘汰算法淘汰了一个key,这个时间主节点模拟一条del命令发送给从节点,从节点收到该命令后,就进行删除key的操作。
Redis 是同步复制还是异步复制?
Redis 使用异步复制(asynchronous replication)。在 Redis 主从复制中,主节点将更新操作发送给从节点,但是从节点并不会立即执行这些更新操作,而是先将它们保存在内存中的复制缓冲区(replication buffer)中,然后异步地执行这些操作
主从复制中两个 Buffer(replication buffer 、repl backlog buffer)有什么区别?
replication buffer 、repl backlog buffer 区别如下:
- 出现的阶段不一样:
- repl backlog buffer 是在增量复制阶段出现,一个主节点只分配一个 repl backlog buffer;
- replication buffer 是在全量复制阶段和增量复制阶段都会出现,主节点会给每个新连接的从节点,分配一个 replication buffer
- 这两个 Buffer 都有大小限制的,当缓冲区满了之后,发生的事情不一样:
- 当 repl backlog buffer 满了,因为是环形结构,会直接覆盖起始位置数据;
- 当 replication buffer 满了,会导致连接断开,删除缓存,从节点重新连接,重新开始全量复制。
