MySQL行级锁加锁规则
MySQL行级锁加锁规则
InnoDB 引擎是支持行级锁的,而 MyISAM 引擎并不支持行级锁,所以后面的内容都是基于 InnoDB 引擎 的。
所以,在说 MySQL 是怎么加行级锁的时候,其实是在说 InnoDB 引擎是怎么加行级锁的。
一致性非锁定读
普通的 select 语句是不会对记录加锁的,因为它属于快照读,是通过 MVCC(多版本并发控制)实现的。
是指InnoDB存储引擎通过行多版本控制(multi versioning)的方式来读取当前执行时间数据库中行的数据。如果读取的行正在执行DELETE或UPDATE操作,这时读取操作不会因此去等待行上锁的释放,相反地,InnoDB存储引擎会去读取行的一个快照数据。
之所以称为非锁定读,是因为不需要等待访问数据行上的X锁的释放。快照数据是指该行之前版本的数据,通过undo段来实现(undo用来在事务中回滚数据)。
在Read Committed和Repeatable Read模式下,innodb存储引擎使用默认的一致性非锁定读。
- 在Read Committed隔离级别下,对于快照数据,一致性非锁定读总是读取被锁定行的最新一份快照数据
- 在Repeatable Read隔离级别下,对于快照数据,一致性非锁定读总是读取事务开始时的行数据版本
一致性锁定读
如果要在查询时对记录加行级锁,可以使用下面这两个方式,这两种查询会加锁的语句称为锁定读。
1 | |
上面这两条语句必须在一个事务中,因为当事务提交了,锁就会被释放,所以在使用这两条语句的时候,要加上 begin 或者 start transaction 开启事务的语句。
**除了上面这两条锁定读语句会加行级锁之外,update 和 delete 操作都会加行级锁,且锁的类型都是独占锁(X型锁)**。
1 | |
下面讨论的情况都是锁定读
MySQL行级锁加锁规则
行级锁加锁规则比较复杂,不同的场景,加锁的形式是不同的。
加锁的对象是索引,加锁的基本单位是 next-key lock,它是由记录锁和间隙锁组合而成的,next-key lock 是前开后闭区间,而间隙锁是前开后开区间。
但是,next-key lock 在一些场景下会退化成记录锁或间隙锁。
那到底是什么场景呢?总结一句,在能使用记录锁或者间隙锁就能避免幻读现象的场景下, next-key lock 就会退化成记录锁或间隙锁。
总结
对于 主键索引 来说:
- 等值条件,命中,则加记录锁
- 等值条件,未命中,则加间隙锁
- 范围条件,命中
- 大于等于加记录锁
- 小于等于加临键锁
- 范围条件,没有命中
- 小于或小于等于加间隙锁
- 大于或大于等于加临键锁
对于 辅助索引 来说:
- 等值条件,命中,则对命中的记录的
辅助索引项和主键索引项加记录锁,辅助索引项两侧加间隙锁 - 等值条件,未命中,则加间隙锁
- 范围条件,对包含 where 条件的临建区间加临键锁,对命中纪录的 id 索引项加记录锁
唯一索引等值查询
当我们用唯一索引进行等值查询的时候,查询的记录存不存在,加锁的规则也会不同:
- 当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会退化成「记录锁」。
- 当查询的记录是「不存在」的,在索引树找到第一条大于该查询记录的记录后,将该记录的索引中的 next-key lock 会退化成「间隙锁」。
记录存在的情况
假设事务 A 执行了这条等值查询语句,查询的记录是「存在」于表中的。
1 | |
那么,事务 A 会为 id 为 1 的这条记录就会加上 X 型的记录锁。
原因就是在唯一索引等值查询并且查询记录存在的场景下,仅靠记录锁也能避免幻读的问题。
幻读的定义就是,当一个事务前后两次查询的结果集,不相同时,就认为发生幻读。所以,要避免幻读就是避免结果集某一条记录被其他事务删除,或者有其他事务插入了一条新记录,这样前后两次查询的结果集就不会出现不相同的情况。
- 由于主键具有唯一性,所以其他事务插入 id = 1 的时候,会因为主键冲突,导致无法插入 id = 1 的新记录。这样事务 A 在多次查询 id = 1 的记录的时候,不会出现前后两次查询的结果集不同,也就避免了幻读的问题。
- 由于对 id = 1 加了记录锁,其他事务无法删除该记录,这样事务 A 在多次查询 id = 1 的记录的时候,不会出现前后两次查询的结果集不同,也就避免了幻读的问题。
记录不存在的情况
假设事务 A 执行了这条等值查询语句,查询的记录是「不存在」于表中的。
1 | |
此时事务 A 在 id = 5 记录的主键索引上加的是间隙锁,锁住的范围是 (1, 5)。

接下来,如果有其他事务插入 id 值为 2、3、4 这一些记录的话,这些插入语句都会发生阻塞。
注意,如果其他事务插入的 id = 1 或者 id = 5 的记录话,并不会发生阻塞,而是报主键冲突的错误,因为表中已经存在 id = 1 和 id = 5 的记录了。
间隙锁的范围(1, 5) ,是怎么确定的?
根据我的经验,如果 LOCK_MODE 是 next-key 锁或者间隙锁,那么 LOCK_DATA 就表示锁的范围「右边界」,此次的事务 A 的 LOCK_DATA 是 5。
然后锁范围的「左边界」是表中 id 为 5 的上一条记录的 id 值,即 1。
因此,间隙锁的范围(1, 5)。
为什么唯一索引等值查询并且查询记录「不存在」的场景下,在索引树找到第一条大于该查询记录的记录后,要将该记录的索引中的 next-key lock 会退化成「间隙锁」?
原因就是在唯一索引等值查询并且查询记录不存在的场景下,仅靠间隙锁就能避免幻读的问题。
- 为什么 id = 5 记录上的主键索引的锁不可以是 next-key lock?如果是 next-key lock,就意味着其他事务无法删除 id = 5 这条记录,但是这次的案例是查询 id = 2 的记录,只要保证前后两次查询 id = 2 的结果集相同,就能避免幻读的问题了,所以即使 id =5 被删除,也不会有什么影响,那就没必须加 next-key lock,因此只需要在 id = 5 加间隙锁,避免其他事务插入 id = 2 的新记录就行了。
- 为什么不可以针对不存在的记录加记录锁?锁是加在索引上的,而这个场景下查询的记录是不存在的,自然就没办法锁住这条不存在的记录。
唯一索引范围查询
范围查询和等值查询的加锁规则是不同的。
当唯一索引进行范围查询时,会对每一个扫描到的索引加 next-key 锁,然后如果遇到下面这些情况,会退化成记录锁或者间隙锁:
情况一:针对「大于等于」的范围查询,要看是否存在存在等值查询的条件
- 如果等值查询的记录是存在于表中,那么该记录的索引中的 next-key 锁会退化成记录锁。
- 如果等值查询的记录不存在与表中,仍然加next-key锁
情况二:针对「小于或者小于等于」的范围查询,要看条件值的记录是否存在于表中
当条件值的记录不在表中,那么不管是「小于」还是「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。
当条件值的记录在表中
- 如果是「小于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁
- 如果「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引 next-key 锁不会退化成间隙锁。其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。
针对「大于或者大于等于」的范围查询
针对「大于」的范围查询的情况
假设事务 A 执行了这条范围查询语句:
1 | |
事务 A 加锁变化过程如下:
- 最开始要找的第一行是 id = 20,由于查询该记录不是一个等值查询(不是大于等于条件查询),所以对该主键索引加的是范围为 (15, 20] 的 next-key 锁;
- 由于是范围查找,就会继续往后找存在的记录,虽然我们看见表中最后一条记录是 id = 20 的记录,但是实际在 Innodb 存储引擎中,会用一个特殊的记录来标识最后一条记录,该特殊的记录的名字叫 supremum pseudo-record ,所以扫描第二行的时候,也就扫描到了这个特殊记录的时候,会对该主键索引加的是范围为 (20, +∞] 的 next-key 锁。
- 停止扫描。
可以得知,事务 A 在主键索引上加了两个 X 型 的 next-key 锁:
结论:不管条件值存不存在,按照范围依次加next-key锁
针对「大于等于」的范围查询的情况
假设事务 A 执行了这条范围查询语句:
1 | |
事务 A 加锁变化过程如下:
- 最开始要找的第一行是 id = 15,由于查询该记录是一个等值查询(等于 15),所以该主键索引的 next-key 锁会退化成记录锁,也就是仅锁住 id = 15 这一行记录。
- 由于是范围查找,就会继续往后找存在的记录,扫描到的第二行是 id = 20,于是对该主键索引加的是范围为 (15, 20] 的 next-key 锁;
- 接着扫描到第三行的时候,扫描到了特殊记录( supremum pseudo-record),于是对该主键索引加的是范围为 (20, +∞] 的 next-key 锁。
- 停止扫描。
可以得知,事务 A 在主键索引上加了三个 X 型 的锁,分别是:
结论:如果条件值存在,该主键索引退化成记录锁,否则,仍然加next-key锁
针对「小于或者小于等于」的范围查询
实验一:针对「小于或小于等于」的范围查询时,查询条件值的记录「不存在」表中的情况。
假设事务 A 执行了这条范围查询语句,注意查询条件值的记录(id 为 6)并不存在于表中。
1 | |
事务 A 加锁变化过程如下:
- 最开始要找的第一行是 id = 1,于是对该主键索引加的是范围为 (-∞, 1] 的 next-key 锁;
- 由于是范围查找,就会继续往后找存在的记录,扫描到的第二行是 id = 5,所以对该主键索引加的是范围为 (1, 5] 的 next-key 锁;
- 由于扫描到的第二行记录(id = 5),满足 id < 6 条件,而且也没有达到终止扫描的条件,接着会继续扫描。
- 扫描到的第三行是 id = 10,该记录不满足 id < 6 条件的记录,所以 id = 10 这一行记录的锁会退化成间隙锁,于是对该主键索引加的是范围为 (5, 10) 的间隙锁。
- 由于扫描到的第三行记录(id = 10),不满足 id < 6 条件,达到了终止扫描的条件,于是停止扫描。
从上面的分析中,可以得知事务 A 在主键索引上加了三个 X 型的锁:
虽然这次范围查询的条件是「小于」,但是查询条件值的记录不存在于表中( id 为 6 的记录不在表中),所以如果事务 A 的范围查询的条件改成 <= 6 的话,加的锁还是和范围查询条件为 < 6 是一样的。
结论:针对「小于或者小于等于」的唯一索引范围查询,如果条件值的记录不在表中,那么不管是「小于」还是「小于等于」的范围查询,扫描到终止范围查询的记录时,该记录中索引的 next-key 锁会退化成间隙锁,其他扫描的记录,则是在这些记录的索引上加 next-key 锁。
针对「小于等于」的范围查询时,查询条件值的记录「存在」表中的情况。
假设事务 A 执行了这条范围查询语句,注意查询条件值的记录(id 为 5)存在于表中。
1 | |
事务 A 加锁变化过程如下:
- 最开始要找的第一行是 id = 1,于是对该记录加的是范围为 (-∞, 1] 的 next-key 锁;
- 由于是范围查找,就会继续往后找存在的记录,扫描到的第二行是 id = 5,于是对该记录加的是范围为 (1, 5] 的 next-key 锁。
- 由于主键索引具有唯一性,不会存在两个 id = 5 的记录,所以不会再继续扫描,于是停止扫描。
从上面的分析中,可以得到事务 A 在主键索引上加了 2 个 X 型的锁:
针对「小于」的范围查询时,查询条件值的记录「存在」表中的情况
如果事务 A 的查询语句是小于的范围查询,且查询条件值的记录(id 为 5)存在于表中。
1 | |
事务 A 加锁变化过程如下:
- 最开始要找的第一行是 id = 1,于是对该记录加的是范围为 (-∞, 1] 的 next-key 锁;
- 由于是范围查找,就会继续往后找存在的记录,扫描到的第二行是 id = 5,该记录是第一条不满足 id < 5 条件的记录,于是**该记录的锁会退化为间隙锁,锁范围是 (1,5)**。
- 由于找到了第一条不满足 id < 5 条件的记录,于是停止扫描。
可以得知,此时事务 A 在主键索引上加了两种 X 型锁:
结论:当条件值的记录在表中
- 如果是「小于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁
- 如果「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引 next-key 锁不会退化成间隙锁。其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。
非唯一索引等值查询
当我们用非唯一索引进行等值查询的时候,因为存在两个索引,一个是主键索引,一个是非唯一索引(二级索引),所以在加锁时,同时会对这两个索引都加锁,但是对主键索引加锁的时候,只有满足查询条件的记录才会对它们的主键索引加锁。
针对非唯一索引等值查询时,查询的记录存不存在,加锁的规则也会不同:
当查询的记录「不存在」时,扫描到第一条不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。
当查询的记录「存在」时,由于不是唯一索引,所以肯定存在索引值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后在扫描的过程中,对扫描到的二级索引记录加的是 next-key 锁,而对于第一个不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁。
记录不存在的情况
假设事务 A 对非唯一索引(age)进行了等值查询,且表中不存在 age = 25 的记录。
1 | |
事务 A 加锁变化过程如下:
- 定位到第一条不符合查询条件的二级索引记录,即扫描到 age = 39,于是**该二级索引的 next-key 锁会退化成间隙锁,范围是 (22, 39)**。
- 停止查询
事务 A 在 age = 39 记录的二级索引上,加了 X 型的间隙锁,范围是 (22, 39)。意味着其他事务无法插入 age 值为 23、24、25、26、….、38 这些新记录。不过对于插入 age = 22 和 age = 39 记录的语句,在一些情况是可以成功插入的,而一些情况则无法成功插入。
插入 age = 22 记录的成功和失败的情况分别如下:
- 当其他事务插入一条 age = 22,id = 3 的记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条是 id = 10、age = 22 的记录,该记录的二级索引上没有间隙锁,所以这条插入语句可以执行成功。
- 当其他事务插入一条 age = 22,id = 12 的记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条是 id = 20、age = 39 的记录,正好该记录的二级索引上有间隙锁,所以这条插入语句会被阻塞,无法插入成功。
插入 age = 39 记录的成功和失败的情况分别如下:
- 当其他事务插入一条 age = 39,id = 3 的记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条是 id = 20、age = 39 的记录,正好该记录的二级索引上有间隙锁,所以这条插入语句会被阻塞,无法插入成功。
- 当其他事务插入一条 age = 39,id = 21 的记录的时候,在二级索引树上定位到插入的位置,而该位置的下一条记录不存在,也就没有间隙锁了,所以这条插入语句可以插入成功。
插入语句在插入一条记录之前,需要先定位到该记录在 B+树 的位置,如果插入的位置的下一条记录的索引上有间隙锁,才会发生阻塞。
当有一个事务持有二级索引的间隙锁 (22, 39) 时,插入 age = 22 或者 age = 39 记录的语句是否可以执行成功,关键还要考虑插入记录的主键值,因为「二级索引值(age列)+主键值(id列)」才可以确定插入的位置,确定了插入位置后,就要看插入的位置的下一条记录是否有间隙锁,如果有间隙锁,就会发生阻塞,如果没有间隙锁,则可以插入成功。
记录存在的情况
假设事务 A 对非唯一索引(age)进行了等值查询,且表中存在 age = 22 的记录。
1 | |
事务 A 加锁变化过程如下:
- 由于不是唯一索引,所以肯定存在值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,最开始要找的第一行是 age = 22,于是对该二级索引记录加上范围为 (21, 22] 的 next-key 锁。同时,因为 age = 22 符合查询条件,于是对 age = 22 的记录的主键索引加上记录锁,即对 id = 10 这一行加记录锁。
- 接着继续扫描,扫描到的第二行是 age = 39,该记录是第一个不符合条件的二级索引记录,所以该二级索引的 next-key 锁会退化成间隙锁,范围是 (22, 39)。
- 停止查询。
可以看到,事务 A 对主键索引和二级索引都加了 X 型的锁:
在 age = 22 和 在 age = 39 这两条记录的二级索引上,加了范围为 (21, 22] 的 next-key 锁和加了范围 (22, 39) 的间隙锁
对于是否能插入age = 21 和 age = 39的记录,要看其id号,如果(age = 21,id < 5)或 (age = 39, id > 20)的记录都可以插入成功,因为这个范围没有锁
同时,事务 A 还对主键索引(INDEX_NAME: PRIMARY )加了X 型的记录锁:在 id = 10 这条记录的主键索引上,加了记录锁,意味着其他事务无法更新或者删除 id = 10 的这一行记录。
为什么需要在(22,39)添加一个间隔锁?
为了避免幻读,因为如果不加这个锁,其他事务是可以添加(age = 22,id > 10)的数据的,这样两次查询会出现数据不一致的情况
非唯一索引范围查询
非唯一索引进行范围查询时,对二级索引记录加锁都是加 next-key 锁,然后对满足条件记录的主键索引加记录锁
1 | |
事务 A 的加锁变化:
- 最开始要找的第一行是 age = 22,虽然范围查询语句包含等值查询,但是这里不是唯一索引范围查询,所以是不会发生退化锁的现象,因此对该二级索引记录加 next-key 锁,范围是 (21, 22]。同时,对 age = 22 这条记录的主键索引加记录锁,即对 id = 10 这一行记录的主键索引加记录锁。
- 由于是范围查询,接着继续扫描已经存在的二级索引记录。扫面的第二行是 age = 39 的二级索引记录,于是对该二级索引记录加 next-key 锁,范围是 (22, 39],同时,对 age = 39 这条记录的主键索引加记录锁,即对 id = 20 这一行记录的主键索引加记录锁。
- 虽然我们看见表中最后一条二级索引记录是 age = 39 的记录,但是实际在 Innodb 存储引擎中,会用一个特殊的记录来标识最后一条记录,该特殊的记录的名字叫 supremum pseudo-record ,所以扫描第二行的时候,也就扫描到了这个特殊记录的时候,会对该二级索引记录加的是范围为 (39, +∞] 的 next-key 锁。
- 停止查询
可以看到,事务 A 对主键索引和二级索引都加了 X 型的锁:
在 age >= 22 的范围查询中,明明查询 age = 22 的记录存在并且属于等值查询,为什么不会像唯一索引那样,将 age = 22 记录的二级索引上的 next-key 锁退化为记录锁?
因为 age 字段是非唯一索引,不具有唯一性,所以如果只加记录锁(记录锁无法防止插入,只能防止删除或者修改),就会导致其他事务插入一条 age = 22 的记录,这样前后两次查询的结果集就不相同了,出现了幻读现象。
为什么主键索引中也需要加锁呢?
如果主键不加锁,其他并发SQL就可以通过主键索引进行修改
1 | |
就会导致这条 update 语句并不知道这条记录已经被锁定
没有加索引的查询
前面的案例,我们的查询语句都有使用索引查询,也就是查询记录的时候,是通过索引扫描的方式查询的,然后对扫描出来的记录进行加锁。
如果锁定读查询语句,没有使用索引列作为查询条件,或者查询语句没有走索引查询,导致扫描是全表扫描。那么,每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表,这时如果其他事务对该表进行增、删、改操作的时候,都会被阻塞。
不只是锁定读查询语句不加索引才会导致这种情况,update 和 delete 语句如果查询条件不加索引,那么由于扫描的方式是全表扫描,于是就会对每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表。
因此,在线上在执行 update、delete、select … for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了,这是挺严重的问题。
假设有两个事务的执行顺序如下:
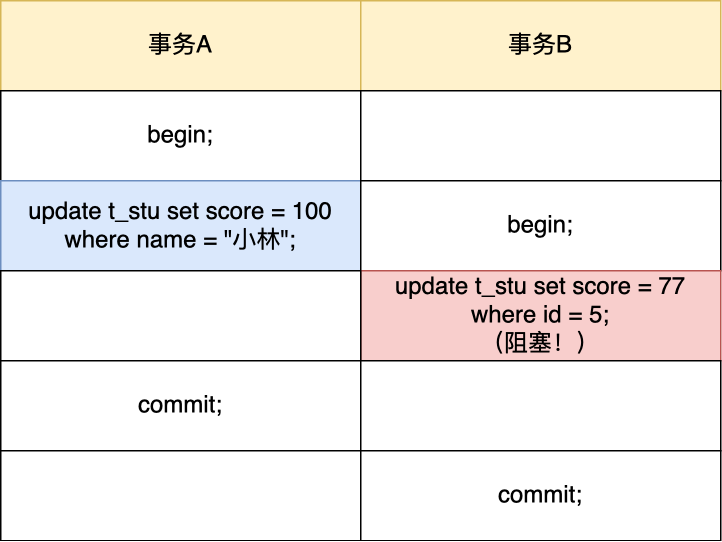
可以看到,这次事务 B 的 update 语句被阻塞了。
这是因为事务 A的 update 语句中 where 条件没有索引列,触发了全表扫描,在扫描过程中会对索引加锁,所以全表扫描的场景下,所有记录都会被加锁,也就是这条 update 语句产生了 4 个记录锁和 5 个间隙锁,相当于锁住了全表。

因此,当在数据量非常大的数据库表执行 update 语句时,如果没有使用索引,就会给全表的加上 next-key 锁, 那么锁就会持续很长一段时间,直到事务结束,而这期间除了 select ... from语句,其他语句都会被锁住不能执行,业务会因此停滞。
那 update 语句的 where 带上索引就能避免全表记录加锁了吗?
并不是。
关键还得看这条语句在执行过程种,优化器最终选择的是索引扫描,还是全表扫描,如果走了全表扫描,就会对全表的记录加锁了。
TIP
网上很多资料说,update 没加锁索引会加表锁,这是不对的。
Innodb 源码里面在扫描记录的时候,都是针对索引项这个单位去加锁的, update 不带索引就是全表扫扫描,也就是表里的索引项都加锁,相当于锁了整张表,所以大家误以为加了表锁。
如何避免这种事故的发生?
我们可以将 MySQL 里的 sql_safe_updates 参数设置为 1,开启安全更新模式。
官方的解释: If set to 1, MySQL aborts UPDATE or DELETE statements that do not use a key in the WHERE clause or a LIMIT clause. (Specifically, UPDATE statements must have a WHERE clause that uses a key or a LIMIT clause, or both. DELETE statements must have both.) This makes it possible to catch UPDATE or DELETE statements where keys are not used properly and that would probably change or delete a large number of rows. The default value is 0.
大致的意思是,当 sql_safe_updates 设置为 1 时。
update 语句必须满足如下条件之一才能执行成功:
- 使用 where,并且 where 条件中必须有索引列;
- 使用 limit;
- 同时使用 where 和 limit,此时 where 条件中可以没有索引列;
delete 语句必须满足以下条件能执行成功:
- 同时使用 where 和 limit,此时 where 条件中可以没有索引列;
如果 where 条件带上了索引列,但是优化器最终扫描选择的是全表,而不是索引的话,我们可以使用 force index([index_name]) 可以告诉优化器使用哪个索引,以此避免有几率锁全表带来的隐患。